使用vue 列表的拖动排序功能,谷歌拖拽没问题,但是在火狐测试时候,拖拽时候能成功,但是在火狐中却会打开了一个新的tab并搜索。搜索后发现了好的解决办法。参考传送
添加以下代码就可以了:
<script>
document.body.ondrop = function (e) {
e.preventDefault();
e.stopPropagation();
}
</script>
二皮博客
使用vue 列表的拖动排序功能,谷歌拖拽没问题,但是在火狐测试时候,拖拽时候能成功,但是在火狐中却会打开了一个新的tab并搜索。
使用vue 列表的拖动排序功能,谷歌拖拽没问题,但是在火狐测试时候,拖拽时候能成功,但是在火狐中却会打开了一个新的tab并搜索。搜索后发现了好的解决办法。参考传送
添加以下代码就可以了:
<script>
document.body.ondrop = function (e) {
e.preventDefault();
e.stopPropagation();
}
</script>
先学安装,再学使用
Docker从1.13版本之后采用时间线的方式作为版本号,分为社区版CE和企业版EE。
社区版是免费提供给个人开发者和小型团体使用的,企业版会提供额外的收费服务,比如经过官方测试认证过的基础设施、容器、插件等。
社区版按照stable和edge两种方式发布,每个季度更新stable版本,如17.06,17.09;每个月份更新edge版本,如17.09,17.10。
1、Docker 要求 CentOS 系统的内核版本高于 3.10 ,查看本页面的前提条件来验证你的CentOS 版本是否支持 Docker 。
通过 uname -r 命令查看你当前的内核版本
$ uname -r
2、使用 root 权限登录 Centos。确保 yum 包更新到最新。
$ sudo yum update
3、卸载旧版本(如果安装过旧版本的话)
$ sudo yum remove docker docker-common docker-selinux docker-engine
4、安装需要的软件包, yum-util 提供yum-config-manager功能,另外两个是devicemapper驱动依赖的
$ sudo yum install -y yum-utils device-mapper-persistent-data lvm2
5、设置yum源
$ sudo yum-config-manager --add-repo https://download.docker.com/linux/centos/docker-ce.repo

6、可以查看所有仓库中所有docker版本,并选择特定版本安装
$ yum list docker-ce --showduplicates | sort -r

7、安装docker
$ sudo yum install docker-ce #由于repo中默认只开启stable仓库,故这里安装的是最新稳定版17.12.0 $ sudo yum install <FQPN> # 例如:sudo yum install docker-ce-17.12.0.ce

8、启动并加入开机启动
$ sudo systemctl start docker $ sudo systemctl enable docker
9、验证安装是否成功(有client和service两部分表示docker安装启动都成功了)
$ docker version

1、因为之前已经安装过旧版本的docker,在安装的时候报错如下:

Transaction check error: file /usr/bin/docker from install of docker-ce-17.12.0.ce-1.el7.centos.x86_64 conflicts with file from package docker-common-2:1.12.6-68.gitec8512b.el7.centos.x86_64 file /usr/bin/docker-containerd from install of docker-ce-17.12.0.ce-1.el7.centos.x86_64 conflicts with file from package docker-common-2:1.12.6-68.gitec8512b.el7.centos.x86_64 file /usr/bin/docker-containerd-shim from install of docker-ce-17.12.0.ce-1.el7.centos.x86_64 conflicts with file from package docker-common-2:1.12.6-68.gitec8512b.el7.centos.x86_64 file /usr/bin/dockerd from install of docker-ce-17.12.0.ce-1.el7.centos.x86_64 conflicts with file from package docker-common-2:1.12.6-68.gitec8512b.el7.centos.x86_64
2、卸载旧版本的包
$ sudo yum erase docker-common-2:1.12.6-68.gitec8512b.el7.centos.x86_64

3、再次安装docker
$ sudo yum install docker-ce
原文地址:https://www.cnblogs.com/yufeng218/p/8370670.html
Memcached的优点:
Memcached可以利用多核优势,单实例吞吐量极高,可以达到几十万QPS(取决于key、value的字节大小以及服务器硬件性能,日常环境中QPS高峰大约在4-6w左右)。适用于最大程度扛量。
支持直接配置为session handle。
Memcached的局限性:
只支持简单的key/value数据结构,不像Redis可以支持丰富的数据类型。
无法进行持久化,数据不能备份,只能用于缓存使用,且重启后数据全部丢失。
无法进行数据同步,不能将MC中的数据迁移到其他MC实例中。
Memcached内存分配采用Slab Allocation机制管理内存,value大小分布差异较大时会造成内存利用率降低,并引发低利用率时依然出现踢出等问题。需要用户注重value设计。
Redis的优点:
支持多种数据结构,如 string(字符串)、 list(双向链表)、dict(hash表)、set(集合)、zset(排序set)、hyperloglog(基数估算)
支持持久化操作,可以进行aof及rdb数据持久化到磁盘,从而进行数据备份或数据恢复等操作,较好的防止数据丢失的手段。
支持通过Replication进行数据复制,通过master-slave机制,可以实时进行数据的同步复制,支持多级复制和增量复制,master-slave机制是Redis进行HA的重要手段。
单线程请求,所有命令串行执行,并发情况下不需要考虑数据一致性问题。
支持pub/sub消息订阅机制,可以用来进行消息订阅与通知。
支持简单的事务需求,但业界使用场景很少,并不成熟。
Redis的局限性:
Redis只能使用单线程,性能受限于CPU性能,故单实例CPU最高才可能达到5-6wQPS每秒(取决于数据结构,数据大小以及服务器硬件性能,日常环境中QPS高峰大约在1-2w左右)。
支持简单的事务需求,但业界使用场景很少,并不成熟,既是优点也是缺点。
Redis在string类型上会消耗较多内存,可以使用dict(hash表)压缩存储以降低内存耗用。
Mc和Redis都是Key-Value类型,不适合在不同数据集之间建立关系,也不适合进行查询搜索。比如redis的keys pattern这种匹配操作,对redis的性能是灾难。
mongoDB 是一种文档性的数据库。先解释一下文档的数据库,即可以存放xml、json、bson类型系那个的数据。
这些数据具备自述性(self-describing),呈现分层的树状数据结构。redis可以用hash存放简单关系型数据。
mongoDB 存放json格式数据。
适合场景:事件记录、内容管理或者博客平台,比如评论系统。
1.mongodb持久化原理
mongodb与mysql不同,mysql的每一次更新操作都会直接写入硬盘,但是mongo不会,做为内存型数据库,数据操作会先写入内存,然后再会持久化到硬盘中去,那么mongo是如何持久化的呢
mongodb在启动时,专门初始化一个线程不断循环(除非应用crash掉),用于在一定时间周期内来从defer队列中获取要持久化的数据并写入到磁盘的journal(日志)和mongofile(数据)处,当然因为它不是在用户添加记录时就写到磁盘上,所以按mongodb开发者说,它不会造成性能上的损耗,因为看过代码发现,当进行CUD操作时,记录(Record类型)都被放入到defer队列中以供延时批量(groupcommit)提交写入,但相信其中时间周期参数是个要认真考量的参数,系统为90毫秒,如果该值更低的话,可能会造成频繁磁盘操作,过高又会造成系统宕机时数据丢失过。
2.什么是NoSQL数据库?NoSQL和RDBMS有什么区别?在哪些情况下使用和不使用NoSQL数据库?
NoSQL是非关系型数据库,NoSQL = Not Only SQL。
关系型数据库采用的结构化的数据,NoSQL采用的是键值对的方式存储数据。
在处理非结构化/半结构化的大数据时;在水平方向上进行扩展时;随时应对动态增加的数据项时可以优先考虑使用NoSQL数据库。
在考虑数据库的成熟度;支持;分析和商业智能;管理及专业性等问题时,应优先考虑关系型数据库。
3.MySQL和MongoDB之间最基本的区别是什么?
关系型数据库与非关系型数据库的区别,即数据存储结构的不同。
4.MongoDB的特点是什么?
(1)面向文档(2)高性能(3)高可用(4)易扩展(5)丰富的查询语言
5.MongoDB支持存储过程吗?如果支持的话,怎么用?
MongoDB支持存储过程,它是javascript写的,保存在db.system.js表中。
6.如何理解MongoDB中的GridFS机制,MongoDB为何使用GridFS来存储文件?
GridFS是一种将大型文件存储在MongoDB中的文件规范。使用GridFS可以将大文件分隔成多个小文档存放,这样我们能够有效的保存大文档,而且解决了BSON对象有限制的问题。
7.为什么MongoDB的数据文件很大?
MongoDB采用的预分配空间的方式来防止文件碎片。
8.当更新一个正在被迁移的块(Chunk)上的文档时会发生什么?
更新操作会立即发生在旧的块(Chunk)上,然后更改才会在所有权转移前复制到新的分片上。
9.MongoDB在A:{B,C}上建立索引,查询A:{B,C}和A:{C,B}都会使用索引吗?
不会,只会在A:{B,C}上使用索引。
10.如果一个分片(Shard)停止或很慢的时候,发起一个查询会怎样?
如果一个分片停止了,除非查询设置了“Partial”选项,否则查询会返回一个错误。如果一个分片响应很慢,MongoDB会等待它的响应。
从以下几个维度,对redis、memcache、mongoDB 做了对比,
1、性能
都比较高,性能对我们来说应该都不是瓶颈
总体来讲,TPS方面redis和memcache差不多,要大于mongodb
2、操作的便利性
memcache数据结构单一
redis丰富一些,数据操作方面,redis更好一些,较少的网络IO次数
mongodb支持丰富的数据表达,索引,最类似关系型数据库,支持的查询语言非常丰富
3、内存空间的大小和数据量的大小
redis在2.0版本后增加了自己的VM特性,突破物理内存的限制;可以对key value设置过期时间(类似memcache)
memcache可以修改最大可用内存,采用LRU算法
mongoDB适合大数据量的存储,依赖操作系统VM做内存管理,吃内存也比较厉害,服务不要和别的服务在一起
4、可用性(单点问题)
对于单点问题,
redis,依赖客户端来实现分布式读写;主从复制时,每次从节点重新连接主节点都要依赖整个快照,无增量复制,因性能和效率问题,
所以单点问题比较复杂;不支持自动sharding,需要依赖程序设定一致hash 机制。
一种替代方案是,不用redis本身的复制机制,采用自己做主动复制(多份存储),或者改成增量复制的方式(需要自己实现),一致性问题和性能的权衡
Memcache本身没有数据冗余机制,也没必要;对于故障预防,采用依赖成熟的hash或者环状的算法,解决单点故障引起的抖动问题。
mongoDB支持master-slave,replicaset(内部采用paxos选举算法,自动故障恢复),auto sharding机制,对客户端屏蔽了故障转移和切分机制。
5、可靠性(持久化)
对于数据持久化和数据恢复,
redis支持(快照、AOF):依赖快照进行持久化,aof增强了可靠性的同时,对性能有所影响
memcache不支持,通常用在做缓存,提升性能;
MongoDB从1.8版本开始采用binlog方式支持持久化的可靠性
6、数据一致性(事务支持)
Memcache 在并发场景下,用cas保证一致性
redis事务支持比较弱,只能保证事务中的每个操作连续执行
mongoDB不支持事务
7、数据分析
mongoDB内置了数据分析的功能(mapreduce),其他不支持
8、应用场景
redis:数据量较小的更性能操作和运算上
memcache:用于在动态系统中减少数据库负载,提升性能;做缓存,提高性能(适合读多写少,对于数据量比较大,可以采用sharding)
MongoDB:主要解决海量数据的访问效率问题
第一次听别人说依赖注入,没听过这么高大上的名词,不明觉厉。刚开始以为是什么sql注入,结果不是,网上搜了一片有意思的介绍。原来一直用的将对象赋值给另一个对象的属性,就是依赖注入。。。
从前有个人叫小明
小明有三大爱好,抽烟,喝酒…… 咳咳,不好意思,走错片场了。应该是逛知乎、玩王者农药和抢微信红包
我们用一段简单的伪代码,来制造一个这样的小明
class Ming extends Person
{
private $_name;
private $_age;
function read()
{
//逛知乎
}
function play()
{
//玩农药
}
function grab()
{
//抢红包
}
}
但是,小明作为一个人类,没有办法仅靠自己就能实现以上的功能,他必须依赖一部手机,所以他买了一台iphone6,接下来我们来制造一个iphone6
class iPhone6 extends Iphone
{
function read($user="某人")
{
echo $user."打开了知乎然后编了一个故事 \n";
}
function play($user="某人")
{
echo $user."打开了王者农药并送起了人头 \n";
}
function grab($user="某人")
{
echo $user."开始抢红包却只抢不发 \n";
}
}
小明非常珍惜自己的新手机,每天把它牢牢控制在手心里,所以小明变成了这个样子
class Ming extends Person
{
private $_name;
private $_age;
public function __construct()
{
$this->_name = '小明';
$this->_age = 26;
}
function read()
{
//…… 省略若干代码
(new iPhone6())->read($this->_name); //逛知乎
}
function play()
{
//…… 省略若干代码
(new iPhone6())->play($this->_name);//玩农药
}
function grab()
{
//…… 省略若干代码
(new iPhone6())->grab($this->_name);//抢红包
}
}
今天是周六,小明不用上班,于是他起床,并依次逛起了知乎,玩王者农药,并抢了个红包。
$ming = new Ming(); //小明起床
$ming->read();
$ming->play();
$ming->grab();
这个时候,我们可以在命令行里看到输出如下
小明打开了知乎然后编了一个故事
小明打开了王者农药并送起了人头
小明开始抢红包却只抢不发
这一天,小明过得很充实,他觉得自己是世界上最幸福的人。
小明和他的手机曾一起度过了一段美好的时光,一到空闲时刻,他就抱着手机,逛知乎,刷微博,玩游戏,他觉得自己根本不需要女朋友,只要有手机在身边,就满足了。
可谁能想到,一次次地系统更新彻底打碎了他的梦想,他的手机变得越来越卡顿,电池的使用寿命也越来越短,一直到某一天的寒风中,他的手机终于耐不住寒冷,头也不回地关了机。
小明很忧伤,他意识到,自己要换手机了。
为了能获得更好的使用体验,小明一咬牙,剁手了一台iphoneX,这部手机铃声很大,电量很足,还能双卡双待,小明很喜欢,但是他遇到一个问题,就是他之前过度依赖了原来那一部iPhone6,他们之间已经深深耦合在一起了,如果要换手机,他就要拿起刀来改造自己,把自己体内所有方法中的iphone6 都换成 iphoneX。
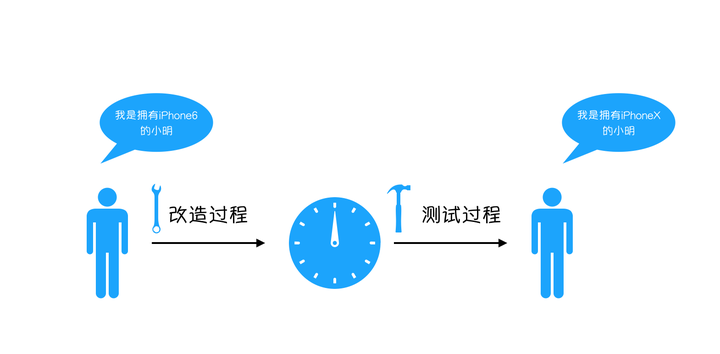
经历了漫长的改造过程,小明终于把代码中的 iphone6 全部换成了 iphoneX。虽然很辛苦,但是小明觉得他是快乐的。
于是小明开开心心地带着手机去上班了,并在回来的路上被小偷偷走了。为了应急,小明只好重新使用那部刚刚被遗弃的iphone6,但是一想到那漫长的改造过程,小明的心里就说不出的委屈,他觉得自己过于依赖手机了,为什么每次手机出什么问题他都要去改造他自己,这不仅仅是过度耦合,简直是本末倒置,他向天空大喊,我不要再控制我的手机了。
天空中的造物主,也就是作为程序员的我,听到了他的呐喊,我告诉他,你不用再控制你的手机了,交给我来管理,把控制权交给我。这就叫做控制反转。
小明听到了我的话,他既高兴,又有一点害怕,他跪下来磕了几个头,虔诚地说到:“原来您就是传说中的造物主,巴格梅克上神。我听到您刚刚说了 控制反转 四个字,就是把手机的控制权从我的手里交给你,但这只是您的想法,是一种思想罢了,要用什么办法才能实现控制反转,又可以让我继续使用手机呢?”
“呵“,身为造物主的我在表现完不屑以后,扔下了四个大字,“依赖注入!”
接下来,伟大的我开始对小明进行惨无人道的改造,如下
class Ming extends Person
{
private $_name;
private $_age;
private $_phone; //将手机作为自己的成员变量
public function __construct($phone)
{
$this->_name = '小明';
$this->_age = 26;
$this->_phone = $phone;
echo "小明起床了 \n";
}
function read()
{
//…… 省略若干代码
$this->_phone->read($this->_name); //逛知乎
}
function play()
{
//…… 省略若干代码
$this->_phone->play($this->_name);//玩农药
}
function grab()
{
//…… 省略若干代码
$this->_phone->grab($this->_name);//抢红包
}
}
接下来,我们来模拟运行小明的一天
$phone = new IphoneX(); //创建一个iphoneX的实例
if($phone->isBroken()){//如果iphone不可用,则使用旧版手机
$phone = new Iphone6();
}
$ming = new Ming($phone);//小明不用关心是什么手机,他只要玩就行了。
$ming->read();
$ming->play();
$ming->grab();
我们先看一下iphoneX 是否可以使用,如果不可以使用,则直接换成iphone6,然后唤醒小明,并把手机塞到他的手里,换句话说,把他所依赖的手机直接注入到他的身上,他不需要关心自己拿的是什么手机,他只要直接使用就可以了。
这就是依赖注入。
小明的生活开始变得简单了起来,而他把省出来的时间都用来写笔记了,他在笔记本上这样写到
我曾经有很强的控制欲,过度依赖于我的手机,导致我和手机之间耦合程度太高,只要手机出现一点点问题,我都要改造我自己,这实在是既浪费时间又容易出问题。自从我把控制权交给了造物主,他每天在唤醒我以前,就已经替我选好了手机,我只要按照平时一样玩手机就可以了,根本不用关心是什么手机。即便手机出了问题,也可以由造物主直接搞定,不需要再改造我自己了,我现在买了七部手机,都交给了造物主,每天换一部,美滋滋!
我也从其中获得了这样的感悟: 如果一个类A 的功能实现需要借助于类B,那么就称类B是类A的依赖,如果在类A的内部去实例化类B,那么两者之间会出现较高的耦合,一旦类B出现了问题,类A也需要进行改造,如果这样的情况较多,每个类之间都有很多依赖,那么就会出现牵一发而动全身的情况,程序会极难维护,并且很容易出现问题。要解决这个问题,就要把A类对B类的控制权抽离出来,交给一个第三方去做,把控制权反转给第三方,就称作控制反转(IOC Inversion Of Control)。控制反转是一种思想,是能够解决问题的一种可能的结果,而依赖注入(Dependency Injection)就是其最典型的实现方法。由第三方(我们称作IOC容器)来控制依赖,把他通过构造函数、属性或者工厂模式等方法,注入到类A内,这样就极大程度的对类A和类B进行了解耦。
这两天在做公司的PC站时因为需要使用angular的$http服务存取数据,而且接口又在另一个域名下面,不得不研究下跨域的问题. 以下把这两天遇到的一些问题总结下.(都是我自己遇到的一些问题, 所以可能不太全面)
Access-Control-Allow-Origin的问题
跨域遇到的第一个问题就是Access-Control-Allow-Origin的错误, Chrome报错Response to preflight request doesn’t pass access control check: No ‘Access-Control-Allow-Origin’ header is present on the requested resource.. 即当前发出请求的域名不在服务器的白名单中, 怎么办呢?
当然,最简单的方法就是在被访问的服务端返回的内容上面加上Access-Control-Allow-Origin响应头, 值为*或是当前网站的域名. 使用*的话虽然方便, 但容易被别的网站乱用,总归有些不太安全; 设置为当前网站的域名的话又只能设置一个. 我的解决办法是设置一个允许的域名白名单, 判断当前请求的refer地址是否在白名单里,如果是,就设置这个地址到Access-Control-Allow-Origin中去,否则就不设置这个响应头.
以下是整理后的代码(实际的白名单列表是写在配置文件中的):
/**
* API扩展
*
* Class ApiTrait
*/
trait ApiTrait
{
/**
* 设置允许跨域访问的域名白名单
*/
protected $_ALLOWED_ORIGINS = [
‘test.icewingcc.com’
];
/**
* 通过指定的参数生成并显示一个特定格式的JSON字符串
*
* @param int|array $status 状态码, 如果是数组,则为完整的输出JSON数组
* @param array $data
* @param string $message
*/
protected function render_json($status = 200, $data = [], $message = ”)
{
/*
* 判断跨域请求,并设置响应头
*/
$cross_origin = $this->_parse_cross_origin_domain();
if($cross_origin){
@header(“Access-Control-Allow-Origin: {$cross_origin}”);
}
/*
* 输出格式化后的内容
*/
echo json_encode([
‘status’ => $status,
‘data’ => $data,
‘message’ => $message
]);
}
/**
* 解析跨域访问, 如果访问来源域名在 config.inc.php 中预定义的允许的列表中,
* 则返回完整的跨域允许域名 , 否则将返回FALSE
*
* @return bool|string
*/
private function _parse_cross_origin_domain()
{
$refer = isset($_SERVER[‘HTTP_REFERER’]) ? $_SERVER[‘HTTP_REFERER’] : ”;
$refer = strtolower($refer);
/*
* 没有来源地址时直接返回false
*/
if(! $refer){
return FALSE;
}
/*
* 解析引用地址, 取出 host 部分
*/
$refer_parts = parse_url($refer);
if(! $refer_parts){
return FALSE;
}
$host = isset($refer_parts[‘host’]) ? $refer_parts[‘host’] : ”;
$scheme = isset($refer_parts[‘scheme’]) ? $refer_parts[‘scheme’] : ‘http’;
if(! $host){
return FALSE;
}
/*
* 检查引用地址是否在预配置的允许跨域域名列表中,如果不在,返回 FALSE
*/
if(in_array($host, $this->_ALLOWED_ORIGINS)){
return ($scheme ? : ‘http’) . ‘://’ . $host;
}
return $host;
}
}
Access-Control-Allow-Headers的问题
以过上面的代码已经实现了跨域中的第一步,GET请求一切正常. 可是需要POST请求发送数据时又出问题了, Chrome报错Request header field Content-Type is not allowed by Access-Control-Allow-Headers in preflight response. 查了下资料,大致意思是请求头中的Content-Type字段内容没有在Access-Control-Allow-Headers中被设置为允许.
这个简单,只需要把这个内容加在Access-Control-Allow-Headers上面就行了,顺便也把其它常用的头都加进去吧.
@header(‘Access-Control-Allow-Headers: Origin, X-Requested-With, Content-Type, Accept, Connection, User-Agent, Cookie’);
搞定.
cookie的问题
用户登录时的POST表单发送问题解决了,紧接着又出现了另一个问题: 系统是通过cookie与后端交互的,而这样跨域时每次请求都是独立的,都会生成不同的cookie. 而cookie里面保存了PHP的session id的信息,自然就无法顺畅的与后端进行交互.
这个处理起来似乎比较麻烦,过程就不说了,最终找到的解决方案是在PHP中再加一个header, 同时JS里也要设置一下:
@header(‘Access-Control-Allow-Credentials: true’);
JS里面也要设置Credentials, 下面是angular的代码, jQuery类似:
$http({
// ….参数们…
withCredentials: true
});
如此一来便解决了跨域时cookie的问题.
OPTIONS请求
以上问题都解决了, 基本上跨域已经搞定, 但仔细看Chrome的Network日志, 发现有些请求会出现两次: 第一次是OPTIONS请求方式, 第二次才是正常的POST. 这个OPTIONS是干嘛的呢?
查了些资料并且测试了下, 发现OPTIONS就是相当于在正式请求接口之前去获取以下header, 自然就是我们前面所设置的那些header. 如果在这次OPTIONS请求中服务器有返回正确的header, 这时才会执行后面真正的请求; 否则请求将会被拒绝, 并抛出错误.
即然这次OPTIONS请求仅仅是为了获取header的, 那么给它一个空的返回就行了呗, 不需要做任何实际的操作.
/*
* 判断 OPTIONS 请求,如果 请求方式为
* OPTIONS ,输出头部直接返回
*/
if(isset($_SERVER[‘REQUEST_METHOD’]) && $_SERVER[‘REQUEST_METHOD’] == ‘OPTIONS’){
$this->render_json([]);
exit();
}
完整代码
下面贴上修改后的完整PHP部分代码, JS就不贴了,加一个参数而已. 仅供参考:
/**
* API扩展
*
* Class ApiTrait
*/
trait ApiTrait
{
/**
* 设置允许跨域访问的域名白名单
*/
protected $_ALLOWED_ORIGINS = [
‘test.icewingcc.com’
];
/**
* 通过指定的参数生成并显示一个特定格式的JSON字符串
*
* @param int|array $status 状态码, 如果是数组,则为完整的输出JSON数组
* @param array $data
* @param string $message
*/
protected function render_json($status = 200, $data = [], $message = ”)
{
/*
* 判断跨域请求,并设置响应头
*/
$cross_origin = $this->_parse_cross_origin_domain();
if($cross_origin){
@header(“Access-Control-Allow-Origin: {$cross_origin}”);
}
@header(‘Access-Control-Allow-Headers: Origin, X-Requested-With, Content-Type, Accept, Connection, User-Agent, Cookie’);
@header(‘Access-Control-Allow-Credentials: true’);
@header(‘Content-type: application/json’);
@header(“Cache-Control: no-cache, must-revalidate”);
/*
* 输出格式化后的内容
*/
echo json_encode([
‘status’ => $status,
‘data’ => $data,
‘message’ => $message
]);
}
/**
* 解析跨域访问, 如果访问来源域名在 config.inc.php 中预定义的允许的列表中,
* 则返回完整的跨域允许域名 , 否则将返回FALSE
*
* @return bool|string
*/
private function _parse_cross_origin_domain()
{
$refer = isset($_SERVER[‘HTTP_REFERER’]) ? $_SERVER[‘HTTP_REFERER’] : ”;
$refer = strtolower($refer);
/*
* 没有来源地址时直接返回false
*/
if(! $refer){
return FALSE;
}
/*
* 解析引用地址, 取出 host 部分
*/
$refer_parts = parse_url($refer);
if(! $refer_parts){
return FALSE;
}
$host = isset($refer_parts[‘host’]) ? $refer_parts[‘host’] : ”;
$scheme = isset($refer_parts[‘scheme’]) ? $refer_parts[‘scheme’] : ‘http’;
if(! $host){
return FALSE;
}
/*
* 检查引用地址是否在预配置的允许跨域域名列表中,如果不在,返回 FALSE
*/
if(in_array($host, $this->_ALLOWED_ORIGINS)){
return ($scheme ? : ‘http’) . ‘://’ . $host;
}
return $host;
}
}
/**
* 基础API访问类
*
* Class BaseApiControl
*/
abstract class BaseApiControl
{
use ApiTrait;
protected function __construct()
{
/*
* 判断 OPTIONS 请求,如果 请求方式为
* OPTIONS ,输出头部直接返回
*/
if(isset($_SERVER[‘REQUEST_METHOD’]) && $_SERVER[‘REQUEST_METHOD’] == ‘OPTIONS’){
$this->render_json([]);
exit();
}
}
// …
}
来源:https://blog.csdn.net/lhorse003/article/details/72625430?utm_source=copy
我们经常在安装和部署SSL证书的时候,需要一同安装中间证书。中间证书到底是什么?为什么必须要安装?为什么有时候,没有中间证书,我的IE也能正常访问HTTPS?为什么其他浏览器都OK了,但安卓手机就是不行了!
中间证书,其实也叫中间CA(中间证书颁发机构,Intermediate certificate authority, Intermedia CA),对应的是根证书颁发机构(Root certificate authority ,Root CA)。为了验证证书是否可信,必须确保证书的颁发机构在设备的可信CA中。如果证书不是由可信CA签发,则会检查颁发这个CA证书的上层CA证书是否是可信CA,客户端将重复这个步骤,直到证明找到了可信CA(将允许建立可信连接)或者证明没有可信CA(将提示错误)。
为了构建信任链,每个证书都包括字段:“使用者”和“颁发者”。 中间CA将在这两个字段中显示不同的信息,显示设备如何获得下一个CA证书,重复检查是否是可信CA。
根证书,必然是一个自签名的证书,“使用者”和“颁发者”都是相同的,所以不会进一步向下检查,如果根CA不是可信CA,则将不允许建立可信连接,并提示错误。
例如:一个服务器证书 domain.com,是由Intermedia CA签发,而Intermedia CA的颁发者Root CA在WEB浏览器可信CA列表中,则证书的信任链如下:
证书 1 – 使用者:domain.com;颁发者:Intermedia CA
证书 2 – 使用者:Intermedia CA;颁发者: Root CA
证书 3 – 使用者:Root CA ; 办法和: Root CA
当Web浏览器验证到证书3:Root CA时,发现是一个可信CA,则完成验证,允许建立可信连接。当然有些情况下,Intermedia CA也在可信CA列表中,这个时候,就可以直接完成验证,建立可信连接。
要获得中间证书,一般有两种方式:第一种、由客户端自动下载中间证书;第二种、由服务器推送中间证书。以下分别讨论。
一张标准的证书,都会包含自己的颁发者名称,以及颁发者机构访问信息: Authority Info Access,其中就会有颁发者CA证书的下载地址。

通过这个URL,我们可以获得这个证书的颁发者证书,即中间证书。Windows、IOS、MAC都支持这种证书获取方式,但Android不支持这种方式,所以,如果我们仅依靠这种方式来获得中间证书,就无法在Android系统上建立可信连接。
除了操作系统支持外,还有一个很重要的因素,就是客户端可以正常访问公网。如果客户端本身在一个封闭的网络环境内,无法访问公网下载中间证书,就会造成失败,无法建立可信连接。
此外,有些CA的中间证书下载地址因为种种原因被“墙”掉了,也会造成我们无法获得中间证书,进而无法建立可信链接。
虽然自动下载中间证书的机制如此不靠谱,但在有些应用中,这却是唯一有效的机制,譬如邮件签名证书,由于我们发送邮件时,无法携带颁发邮件证书的中间证书,往往只能依靠客户端自己去下载中间证书,一旦这个中间证书的URL无法访问(被“墙”掉)就会造成验证失败。
服务器推送中间证书,就是将中间证书,预先部署在服务器上,服务器在发送证书的同时,将中间证书一起发给客户端。我们部署证书,首先就要找到颁发服务器证书的中间证书,可以用中间证书下载工具 。
如果我们在服务器上不主动推送中间证书,可能会造成的问题
虽然我们不部署中间证书,在大多数情况,我们依然可以建立可信的HTTPS连接,但为了避免以上这些情况,我们必须在服务器上部署中间证书。
所以,为了确保我们在各种环境下都能建立可信的HTTPS连接,我们应该尽量做到以下几点:
1、必须在服务器上部署正确的中间证书,以确保各类浏览器都能获得完整的证书链,完成验证。
2、选择可靠的SSL服务商,有些小的CA机构,因为各种原因,造成他们的中间证书下载URL被禁止访问,即使我们在服务器上部署了中间证书,但也可能存在某种不可测的风险,这是我们应该尽力避免的。
3、中间证书往往定期会更新,所以在证书续费或者重新签发后,需要检查是否更换过中间证书。
今天要跟大家讲的是html代码中的nofollow属性,事实上在一般的中小企业网站中基本用不上,但对于内容更新频繁且数量较大的资讯型网站来说还是很有帮助的。
nofollow是什么意思
先来看看nofollow是什么意思,作为A链接的属性值,nofollow的意义在于告诉搜索引擎不要追踪设置了nofollow属性的链接url。举个例子:<a href=”http://www.abs.com/abc.html” rel=”nofollow”>signin</a>,这里就告诉搜索引擎不要追踪http://www.abs.com/abc.html这个链接。
另外,nofollow也可以设置在网页元标记中,如<meta name=”robots” content=”nofollow” />,意思就是告诉搜索引擎不要追踪该页面上所有的链接。这种用法基本很少用到,笔者在本文不做过多的介绍。
从上面的内容我们不难总结,nofollow标签最基本的意义在于告诉搜索引擎不要追踪某些具体的链接。
nofollow怎么用
在明白nofollow的概念和基本意义之后,我们再来看看nofollow怎么用。上面有提到nofollow有两种基本用法,一种是写在meta里,只是这种极少用;另一种则是写在A链接里。
页面上有很多链接,对于这些链接哪些应该使用nofollow标签,是我们需要考虑的,笔者简单的介绍几种nofollow典型的用法。
1.底部链接。尤其是在商城网站中,底部往往会有类似“关于我们”、“投诉建议”、“免责声明”、“帮助中心”等等链接。这些链接对于用户来说有帮助,但是对于搜索来,并没有搜索需求,因此这些页面也就不需要被收录排名,可以使用nofollow。
2.类似“阅读更多”的链接。比如首页文章列表,列出了固定条数后有时候会做一个“阅读更多”的链接,这样的链接方便用户点击,但对搜索引擎来说并没有好的意义,因此链接也可以使用nofollow。
3.正常链接。如果页面内容相对少且更新不是很频繁,那么是否使用nofollow并无区别,如果内容多更新快,为了让更多的新链接被搜索引擎抓取,可以通过设置某些链接(已经被收录的页面链接)的nofollow来促进其他链接被抓取。
关于nofollow的做法,上面说了3种使用到nofollow的情况,这么做的目的是什么,有什么作用,笔者从三个方面说明。
1.节约蜘蛛抓取量。我们知道搜索引擎蜘蛛对网站页面链接的抓取配额有限,对于那些不需要被收录的页面(或者已经被收录的页面)链接我们设置了nofollow,那么就可以把这些配额用到其他需要被抓取收录的页面链接上,这就有利于重要页面的收录。
2.防止权重分散。页面上每个链接都附带了一定的权重,权重是分散的,如果对于那些不重要的页面设置了nofollow,那么就可以把这一部分的权重分配到其他链接身上,提高其他链接的权重。
这里需要注意:关于权重百度官方并没有明确说明,这里只是根据经验讲述。
3.锚文本统一。类似“阅读更多”这样的链接,虽说用户体验好,但是无形中也造成了链接锚文本的多样性,如果文本内容极为相关还行,否则就会导致权重分散。设置了nofollow的话,这个问题可以得到完美解决,又不会影响用户体验。
最后总结:nofollow有其特别的用处,但建议大家不要强求,不要为了nofollow而去制造一些nofollow出来,本站就没有使用。
另外,在友情链接上不要使用nofollow属性,在跟别人交换链接的时候也需要检查对方是否使用了nofollow。
各浏览器useragent记录
window.navigator.userAgent
1) Chrome
Win7:
Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/535.1 (KHTML, like Gecko) Chrome/14.0.835.163 Safari/535.1
2) Firefox
Win7:
Mozilla/5.0 (Windows NT 6.1; WOW64; rv:6.0) Gecko/20100101 Firefox/6.0
3) Safari
Win7:
Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/534.50 (KHTML, like Gecko) Version/5.1 Safari/534.50
4) Opera
Win7:
Opera/9.80 (Windows NT 6.1; U; zh-cn) Presto/2.9.168 Version/11.50
5) IE
Win7+ie9:
Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Win64; x64; Trident/5.0; .NET CLR 2.0.50727; SLCC2; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; InfoPath.3; .NET4.0C; Tablet PC 2.0; .NET4.0E)
Win7+ie8:
Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 6.1; WOW64; Trident/4.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; .NET4.0C; InfoPath.3)
WinXP+ie8:
Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 5.1; Trident/4.0; GTB7.0)
WinXP+ie7:
Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1)
WinXP+ie6:
Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1)
6) 傲游
傲游3.1.7在Win7+ie9,高速模式:
Mozilla/5.0 (Windows; U; Windows NT 6.1; ) AppleWebKit/534.12 (KHTML, like Gecko) Maxthon/3.0 Safari/534.12
傲游3.1.7在Win7+ie9,IE内核兼容模式:
Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.1; WOW64; Trident/5.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; InfoPath.3; .NET4.0C; .NET4.0E)
7) 搜狗
搜狗3.0在Win7+ie9,IE内核兼容模式:
Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.1; WOW64; Trident/5.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; InfoPath.3; .NET4.0C; .NET4.0E; SE 2.X MetaSr 1.0)
搜狗3.0在Win7+ie9,高速模式:
Mozilla/5.0 (Windows; U; Windows NT 6.1; en-US) AppleWebKit/534.3 (KHTML, like Gecko) Chrome/6.0.472.33 Safari/534.3 SE 2.X MetaSr 1.0
8) 360
360浏览器3.0在Win7+ie9:
Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; WOW64; Trident/5.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; InfoPath.3; .NET4.0C; .NET4.0E)
9) QQ浏览器
QQ浏览器6.9(11079)在Win7+ie9,极速模式:
Mozilla/5.0 (Windows NT 6.1) AppleWebKit/535.1 (KHTML, like Gecko) Chrome/13.0.782.41 Safari/535.1 QQBrowser/6.9.11079.201
QQ浏览器6.9(11079)在Win7+ie9,IE内核兼容模式:
Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.1; WOW64; Trident/5.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; InfoPath.3; .NET4.0C; .NET4.0E) QQBrowser/6.9.11079.201
10) 阿云浏览器
阿云浏览器1.3.0.1724 Beta(编译日期2011-12-05)在Win7+ie9:
Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; WOW64; Trident/5.0)
redis-cli --rawmysql语句分析,查看索引使用情况
explain select * from user
explain extended select * from user| id | SELECT识别符。这是SELECT的查询序列号 |
| select_type | SELECT类型,可以为以下任何一种:
|
| table | 输出的行所引用的表 |
| type | 联接类型。下面给出各种联接类型,按照从最佳类型到最坏类型进行排序:
|
| possible_keys | 指出MySQL能使用哪个索引在该表中找到行 |
| key | 显示MySQL实际决定使用的键(索引)。如果没有选择索引,键是NULL。 |
| key_len | 显示MySQL决定使用的键长度。如果键是NULL,则长度为NULL。 |
| ref | 显示使用哪个列或常数与key一起从表中选择行。 |
| rows | 显示MySQL认为它执行查询时必须检查的行数。多行之间的数据相乘可以估算要处理的行数。 |
| filtered | 显示了通过条件过滤出的行数的百分比估计值。 |
| Extra | 该列包含MySQL解决查询的详细信息
|
文章来源:https://blog.csdn.net/u010061060/article/details/52473244/

